
|
||||
| Figure: 1: Blend bewteen wire-frame view and textured view of the body model. | ||||
|
|
||||
| Figure: 1: Blend bewteen wire-frame view and textured view of the body model. | ||||
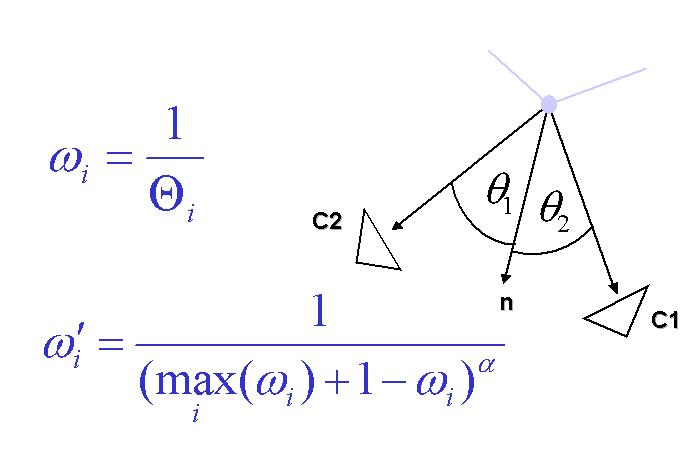
|
|
|||
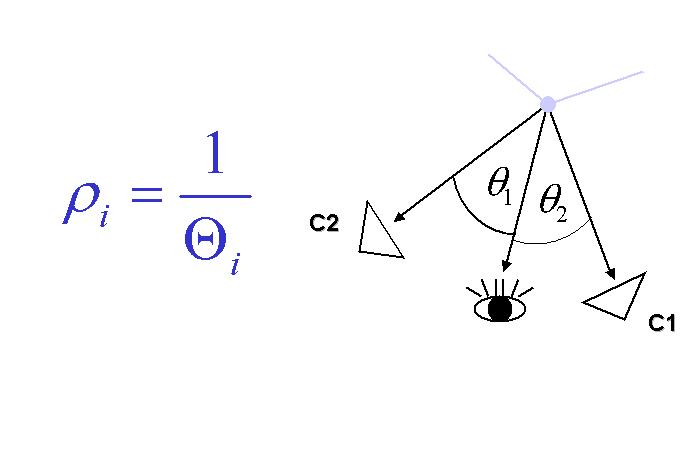
| Figure: 2: Spatial per-vertex blending weights computed in a view-independent (left) and view-dependent (right) way. | ||||

|
||||
| Figure: 1: Rendered novel viewpoint (large) with 2 input camera views (small). | ||||