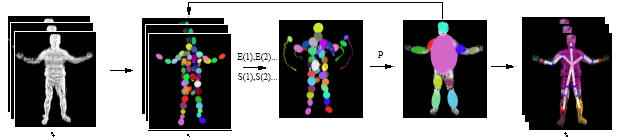
Automatic Marker-free Kinematic Skeleton Reconstruction
In computer animation, human motion capture from video is a
widely used technique to acquire motion parameters. The acquisition process
typically requires an intrusion into the scene in the form of optical markers
which are used to estimate the parameters of motion as well as the kinematic
structure of the performer. Marker-free optical motion capture approaches
exist, but due to their dependence on a specific type of a-priori model they can
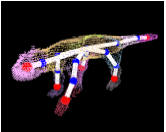
hardly be used to track other subjects, e.g. animals. To bridge the gap between
the generality of marker-based methods and the applicability of marker-free
methods we study a flexible nonintrusive approach that estimates both, a
kinematic model and its parameters of motion from a sequence of voxel-volumes.
The volume sequences are reconstructed from multi-view video data by means of a
shape from-silhouette technique. The method [1] is well-suited for but not
limited to motion capture of human subjects.
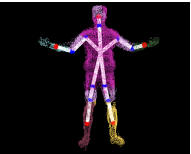
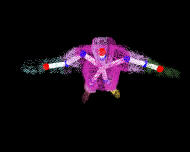
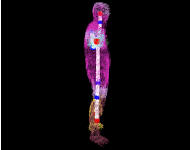
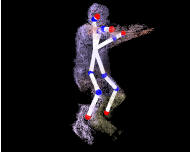
For realistic animation of an artificial character a body model
that represents the character’s kinematic structure is required. Hierarchical
skeleton models are widely used which represent bodies as chains of bones with
interconnecting joints. In video motion capture, animation parameters are
derived from the performance of a subject in the real world. For this
acquisition procedure too, a kinematic body model is required. Typically, the
generation of such a model for tracking and animation is, at best, a
semi-automatic process. We study a novel approach that estimates a hierarchical
skeleton model of an arbitrary moving subject from sequences of voxel data that
were reconstructed from multi-view video footage. Our method [2] does not
require a-priori information about the body structure.


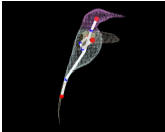
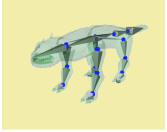
References: