In this work, we explore egocentric whole-body motion capture using a single fisheye camera,
which simultaneously estimates human body and hand motion.
This task presents significant challenges due to three factors, the lack of high-quality datasets,
fisheye camera distortion, and human body self-occlusion.
To address these challenges, we propose a novel approach that leverages FisheyeViT
to extract fisheye image features, which are subsequently converted into pixel-aligned 3D
heatmap representations for 3D human body pose prediction.
For hand tracking, we incorporate
dedicated hand detection and hand pose estimation networks for regressing 3D hand poses.
Finally, we develop a diffusion-based whole-body motion prior model to refine the estimated whole-body
motion while accounting for joint uncertainties.
To train these networks, we collect a large synthetic
dataset, EgoWholeBody, comprising 840,000 high-quality egocentric images captured across a diverse range
of whole-body motion sequences.
Quantitative and qualitative evaluations demonstrate the effectiveness of our method in producing
high-quality whole-body motion estimates from a single egocentric camera.
Main Video
Method
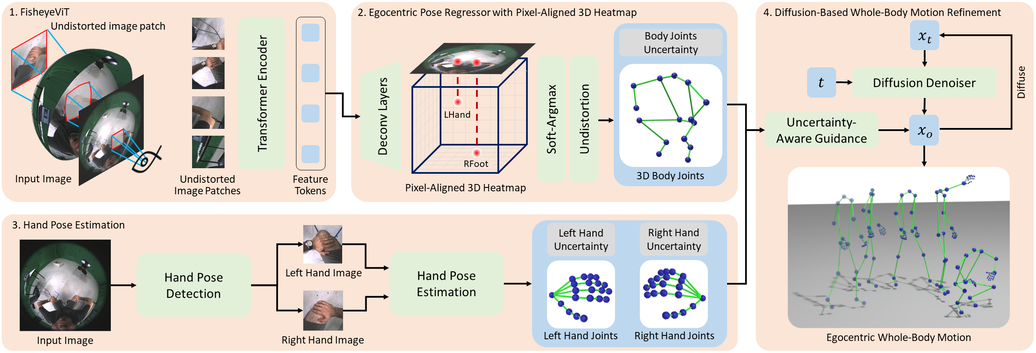
We propose Fisheye VIT to address the Fisheye camera distortion issue.
We first project the fisheye image to a semi-sphere and undistort image patches from the fisheye image.
Then the undistorted patches are sent to the transformer network to get image features.
Here we show the undistorted image patches and how the image patch moves on the fisheye camera.
Next, we propose an egocentric pose regressor with a pixel-aligned 3D heatmap.
We first use deconvolutional layers to obtain the pixel-aligned 3D heatmap.
The voxels in the heatmap directly correspond to pixels in 2D features, subsequently linking to image patches in Fisheye VIT.
Joint positions from the pixel-aligned 3D heatmap are finally transformed with the fisheye camera model to obtain the 3D body poses.
To overcome the challenges of self-occlusion, we propose a diffusion-based motion refinement method.
We first train a diffusion model to learn the whole-body motion prior.
Then, we extract the joint uncertainties from the pixel-aligned 3D heatmap and use them to guide the refinement of the whole-body motion.
Our whole-body motion diffusion model refines joints with high uncertainty by conditioning on joints with low uncertainty.
Here we show the example motion sequences unconditionally generated from the diffusion-based whole-body motion prior.
In response to the absence of egocentric whole-body motion capture datasets, we present EgoWholeBody,
a new large-scale synthetic dataset containing various whole-body motions. Here we show several examples.
Comparisons: Body Motion
Comparisons: Hand Motion
Citation
@article{wang2023egocentric,
title={Egocentric Whole-Body Motion Capture with FisheyeViT and Diffusion-Based Motion Refinement},
author={Wang, Jian and Cao, Zhe and Luvizon, Diogo and Liu, Lingjie and Sarkar, Kripasindhu and Tang, Danhang and Beeler, Thabo and Theobalt, Christian},
journal={arXiv preprint arXiv:2311.16495},
year={2023}
}