Homepage
Contact

Mallikarjun B R
(M. Byrasandra Ramalinga Reddy)
Max-Planck-Institut für InformatikD6: Visual Computing and Artificial Intelligence
| office: |
Campus E1 4,
Room 211B Saarland Informatics Campus 66123 Saarbrücken Germany |
| email: |
mbr@mpi-inf.mpg.de |
| phone: | +49 681 9325 4056 |
| fax: | +49 681 9325 4099 |
Research Interests
- Computer Vision
- Computer Graphics
Publications

|
LiveHand: Real-time and Photorealistic Neural Hand Rendering
Akshay Mundra,
Mallikarjun B R,
Jiayi Wang,
Marc Habermann,
Christian Theobalt and
Mohamad Elgharib International Conference on Computer Vision 2023 (ICCV) — ICCV 2023 [paper] [project page] |
 |
State of the Art in Dense Monocular Non-Rigid 3D Reconstruction
Edith Tretschk*,
Navami Kairanda*,
Mallikarjun B R,
Rishabh Dabral,
Adam Kortylewski,
Bernhard Egger,
Marc Habermann,
Pascal Fua,
Christian Theobalt,
Vladislav Golyanik
This survey focuses on state-of-the-art methods for dense non-rigid 3D reconstruction of various deformable objects and composite scenes from monocular videos or sets of monocular views. It reviews the fundamentals of 3D reconstruction from 2D image observations. We then start from general methods, and proceed towards techniques making stronger assumptions about the observed objects (e.g. human faces, bodies, hands, and animals). We conclude by discussing open challenges in the field and the social aspects associated with the usage of the reviewed methods.
Eurographics 2023 (STAR Report)
[Project Page] [arXiv] |

|
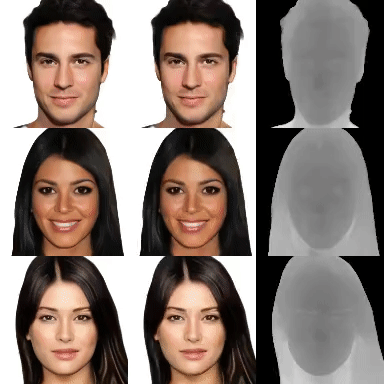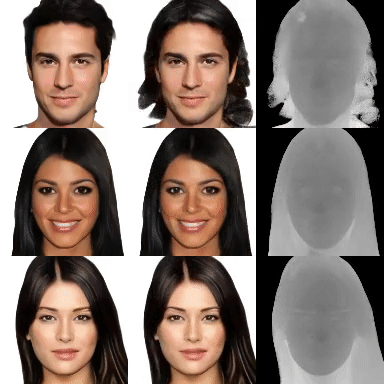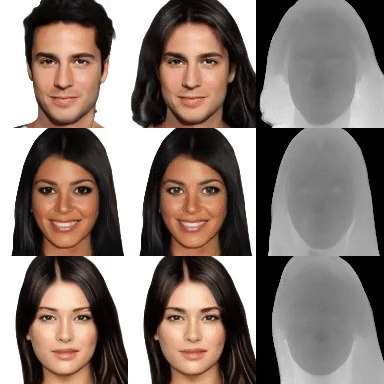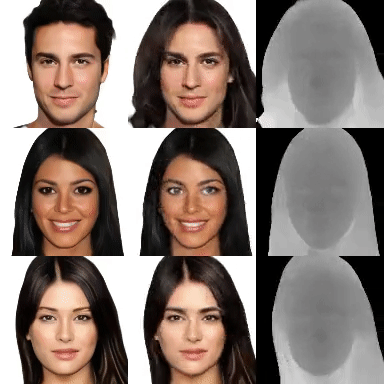
VoRF: Volumetric Relightable Faces
P. Rao,
M. B R,
G. Fox,
T. Weyrich,
B. Bickel,
H. Pfister,
W. Matusik,
A. Tewari,
C. Theobalt and
M. Elgharib British Machine Vision Conference 2022 (BMVC) — BMVC 2022 (Best Paper Award Honourable Mention) We present a volumetric relightable head model, which can igeneralize to unseen identities, even with a single input image. [paper] [project page] |
|
gCoRF: Generative Compositional Radiance Fields
M. B R,
A. Tewari,
X. Pan,
M. Elgharib and
C. Theobalt International Conference on 3D Vision (3DV) — 3DV 2022 (Spotlight) We present a compositional generative model, where each semantic part of the object is represented as an independent 3D representation learnt from only in-the-wild 2D data. [paper] [project page] |

|
Disentangled3D: Learning a 3D Generative Model with Disentangled Geometry and Appearance from Monocular Images
A. Tewari,
M. B R,
X. Pan,
O. Fried and
M. Agarwala and
C. Theobalt Proc. Computer Vision and Pattern Recognition 2022 — CVPR 2022 We design a 3D GAN which can learn a disentangled model of objects, just from monocular observations. Our model can disentangle the geometry and appearance variations in the scene, i.e., we can independently sample from the geometry and appearance spaces of the generative model. [paper] [project page] |
Education
|