
Homepage
Contact

Dr. Vladislav Golyanik
Senior Researcher and Group Leader
4D and Quantum Vision
Max-Planck-Institut für InformatikD6: Visual Computing and Artificial Intelligence
| office: |
Campus E1 4,
Room 219 Saarland Informatics Campus 66123 Saarbrücken Germany |
| email: | golyanik at mpi hyphen inf dot mpg dot de |
| phone: | +49 681 9325-4505 |
| fax: | +49 681 9325-7505 |
NEWS
- [New] 25.06.25: Papers accepted at ICCV 2025 on the role of rear cameras for egocentric 3D human pose estimation and full-body human relighting from OLAT images.
- [New] 12.06.25: Invited Talk at the CVPR 2025 Workshop on Event-based Vision.
- [New] 19.05.25: Invited Talk at ICL on "4D Vision: From Sparse to Dense Reconstruction and Related Problems" (hosted by T. Birdal).
- [New] 12.05.25: Invited Tutorial on "Virtual Humans and Quantum-enhanced Computer Vision" at Eurographics 2025.
- 20.03.2025: Guest lecture at Princeton University: "Advanced Concepts in Neural Rendering and Reconstruction" (by Thomas Leimkuehler and myself).
- 01.03.2025: Papers accepted at CVPR 2025 on 3D Synthesis of Bimanual Interaction, Solving Composite and Binary-Parametrised Problems on Quantum Annealers, Fine-Grained Monocular Non-rigid 3D Surface Tracking and Diffusion Models for Shape Correspondence.
- 02.01.2025: Invited Speaker at the ELIAS-ELLIS-VISMAC Winter School 2025 on Computer Vision, Pattern Recognition and Machine Learning.
- 02.12.2024: Invited Talk "Several Recent Results in 4D Reconstruction and Generative Modelling" at the Australian Institute for Machine Learning (AIML; hosted by T.-J. Chin and S. Lucey).
- 07.10.2024: Invited Talk "3D Reconstruction and Generative Modelling of Non-rigid Scenes at the 4DQV Research Group" at Politecnico Milano (hosted by L. Magri and F. Aggironi).
- 10.09.2024: Invited Tutorial at GCPR 2024 on Virtual Humans and Quantum-enhanced Computer Vision (QeCV). The slides on Quantum-enhanced Computer Vision can be accessed here.
- 04.09.2024: Invited lecture on Quantum-Enhanced Computer Vision at the 3rd European Summer School on Quantum AI (EQAI 2024).
- 17.06.2024: Keynote speaker at the Physics Based Vision meets Deep Learning (PBDL) Workshop at CVPR 2024.
- 31.05.2024: Invited talk at 3D Vision Summer School (3DVSS) 2024 (slides).
- 15.04.2024: I am co-organising two workshops at ECCV 2024:
- 25.03.2024: We contributed two state-of-the-art reports at EUROGRAPHICS'24:
- Po, Yifan, Golyanik et al. State of the Art on Diffusion Models for Visual Computing.
- Yunus et al. Recent Trends in 3D Reconstruction of General Non-Rigid Scenes.
- 08.03.2024: We released UnrealEgo Benchmark for stereo egocentric 3D human pose estimation!
- 01.03.2024: Papers accepted at CVPR 2024:
- 16.10.2023: Papers accepted at 3DV 2024:
- 3D Pose Estimation of Two Interacting Hands from a Monocular Event Camera (Spotlight).
- Quantum-Hybrid Stereo Matching With Nonlinear Regularization and Spatial Pyramids.
- SceNeRFlow: Time-Consistent Reconstruction of General Dynamic Scenes.
- ROAM: Robust and Object-aware Motion Generation using Neural Pose Descriptors.
- MACS: Mass-Conditioned 3D Hand and Object Motion Synthesis.
- 15.09.2023: 4DQV/VCAI contributed two journal and one conference proceedings papers to SIGGRAPH Asia 2023:
- 25.08.2023: I am organising a seminar on Quantum Computer Vision and Machine Learning (QCVML) in WiSe 23/24.
- 18.08.2023: We are organising a lecture on Advanced Topics in Neural Rendering and 3D Reconstruction (3CP) in WiSe 23/24.
- 03.03.2023: Five papers at CVPR 2023 in Vancouver. Many thanks to all students, interns and collaborators!
- EventNeRF: Neural Radiance Fields from a Single Colour Event Camera.
- MoFusion: A Framework for Denoising-Diffusion-based Motion Synthesis (CVPR Highlight).
- Self-supervised Pre-training with Masked Shape Prediction for 3D Scene Understanding.
- Quantum Multi-Model Fitting (CVPR Highlight).
- CCuantuMM: Cycle-Consistent Quantum-Hybrid Matching of Multiple Shapes.
- 31.01.2023: We will organise the CVMLCG Seminar 2023.
- 21.01.2023: A paper on quantum annealing with machine learning is accepted at ICLR 2023 (Oral).
- 22.12.2022: A state of the art report (STAR) conditionally accepted at EUROGRAPHICS 2023.
- 16.12.2022: We are going to organise a Workshop on Quantum Computer Vision and Machine Learning at CVPR 2023; in collaboration with Tongyang Li, Jan-Nico Zaech, Martin Danelljan, Jacob Biamonte and Tolga Birdal. More details coming soon.
- 13.12.2022: Two articles conditionally accepted at EUROGRAPHICS 2023.
- 08.12.2022: V. Golyanik gave a talk titled Advances in Quantum Computer Vision at the Workshop on Quantum Information at Saarland University (event poster). The slides can be found here. Many thanks to the organisers for making such an event happen!
- 21.10.2022: An article on random number generation on quantum annealers accepted at IEEE Access.
- 05.10.2022: The source code of MoCapDeform is now available here: github link.
- 30.09.2022: A paper on high-fidelity 3D human performance capture accepted at BMVC 2022.
- 12.09.2022: MoCapDeform received Best Student Paper Award at 3DV 2022.
- 05.08.2022: A paper on global 3D human motion capture (MoCapDeform) accepted at 3DV 2022.
- 25.07.2022: 4DQV will present several papers at ECCV 2022:
- 04.07.2022: The source code of Physical Inertial Poser (PIP) is now available here: github link.
- 27.06.2022: The source code of φ-SfT is now available here: github link.
- 21.04.2022: The source code of Neural PhysCap is now available via github.
- 19.02.2022: We are co-organising a tutorial associated with our STAR on Advances in Neural Rendering on the 27th of April at EUROGRAPHICS'22.
- 28.03.2022: 4DQV will present three papers at CVPR 2022:
- 11.02.2022: State of the art report on neural rendering (the updated version) accepted at EUROGRAPHICS'22.
- 25.10.2021: The source code of Convex Joint Graph Matching and Clustering via Semidefinite Relaxations is released.
- 18.10.2021: An article is accepted at TPAMI (HandVoxNet++). Our method is ranked first on the HANDS19 challenge dataset (Task 1: Depth-Based 3D Hand Pose Estimation) as of August 2020.
- 17.10.2021: Two papers accepted at 3DV 2021 (about graph matching and clustering and human image generation).
- 13.10.2021: EventHands is mentioned in ICCV 2021 Daily.
- 12.10.2021: The source code of GraviCap is released on github.
- 11.10.2021: We have launched the 4DQV group's web page. Check open positions.
- 11.10.2021: The source code of Q-Match is released on github.
- 27.09.2021: The source code of EventHands is released on github.
- 08.09.2021: Dennis Willsch gave a 4DQV Lecture Series talk titled Applications on Quantum Annealers at Jülich Supercomputing Centre. The video can be found here.
- 19.08.2021: We are going to present the following works at ICCV 2021: GraviCap, Non-Rigid Neural Radiance Fields, Iterative Shape Matching via Quantum Annealing and EventHands.
- 05.07.2021: The source code of PhysCap is now available here.
- 03.05.2021: I am starting a research group on 4D and quantum computer vision and accepting now applications for PhD positions, post-doc positions and internships (including theses internships and remote internships).
- 29.04.2020: An article accepted at SIGGRAPH 2021 ("Neural Physcap").
- 19.04.2020: Our work on monocular template-based non-rigid 3D tracking from a single event stream is accepted at CVPR 2021 Workshop on Event-based Vision.
- 30.03.2021: We are going to present three papers at CVPR 2021 (on quantum multi-matching, human motion transfer and human animation from a single image).
- 18.02.2021: Computer Vision and Machine Learning for Computer Graphics, SS 2021, Saarland University.
- 04.02.2021: The source code of PatchNets is now available (github link).
- 30.12.2020: The source code of Non-Rigid Neural Radiance Fields (NR-NeRF) is available (github link).
- 15.10.2020: Three papers accepted to 3DV 2020 (dense NRSfM, quantum graph matching and point set alignment).
- 29.09.2020: Our work on egocentric videoconferencing using a new device with a fisheye camera is accepted at SIGGRAPH Asia 2020.
- 27.08.2020: Our work on physically principled 3D human motion capture in real time is accepted at SIGGRAPH Asia.
- 24.08.2020: Our paper "Neural Re-Rendering of Humans from a Single Image" is featured in "ECCV 2020 Daily".
Open Positions
- PhD positions, post-doc positions and internships are available. Check how to apply.
- If you are interested in a bachelor/master thesis, an internship, research immersion lab (RIL) or a HiWi position on one of the topics listed below, do not hesitate to reach me out.
Research Profile
-
I am currently leading "4D and Quantum Vision" group at Max Planck Institute for Informatics, D6 Department. Our primary principles are 1) quality first in pursuit of scientific innovation and 2) maintaining an inclusive and collaborative environment.
- 3D Reconstruction and Neural Rendering of Non-Rigid Scenes (= 4D Object and Scene Reconstruction)
- 4D Generative Models
- Quantum-enhanced Computer Vision (QeCV) (predominantly 3D)
- Area Chair (CVPR 2025, ECCV 2024)
- IPC at EUROGRAPHICS 2024 and 2025
- Doctoral Consortium Mentor at EUROGRAPHICS 2025
- Associate Editor of IJCV
- IJCV: Special Issue on Traditional Computer Vision in the Age of Deep Learning (Guest Editor)
- IEEE CG&A, Special Issue on Quantum Visual Computing (Guest Editor)
- TradiCV workshop at ECCV 2024 (Co-organiser)
- QCVML workshops at CVPR 2023 and ECCV 2024 (Co-organiser)
- PhD thesis reviewer (Latest: University of Trento; IIT Bombay; Rey Juan Carlos University)
- Advisory Board: IW-P3HSE Workshop at IEEE ISMAR 2024
Our world is inherently non-rigid at different spatial and temporal scales. Reconstructing it in 4D (3D+time) from visual observations remains challenging and has many practical applications. The challenges concern ill-posedness of the observations (e.g., monocular, which is of special interest) and scene conditions (e.g., partial observations, low light or high-speed motions), among others. To address those, 4DQV develops innovative approaches using RGB and event cameras for novel-view synthesis of deformable objects, humans and scenes; dense 3D deformation capture; sparse 3D pose estimation (hands and bodies); and generative 3D and video techniques. Furthermore, as a long-term goal, we investigate the advantages of quantum computational paradigms in solving combinatorial optimisation problems or providing alternatives to parameter-heavy neural networks in vision (e.g., in 3D scene representations learning, model fitting and mesh alignment aimed towards 4D reconstruction).
My research interests include:
Community service and recent event organisation:
Slides/Recordings of Recent Talks
- 12.06.26: Invited Talk at the CVPR 2025 Workshop on Event-based Vision on Event-based Non-rigid 3D Reconstruction and Novel-View Synthesis.
- 19.05.25: Invited Talk at ICL on 4D Vision: From Sparse to Dense Reconstruction and Related Problems.
- 10.09.2024: Slides on Quantum-enhanced Computer Vision (Part 2 of the Joint Tutorial at GCPR 2024).
- 17.06.2024: Keynote at CVPR 2024 (PDBL Workshop): Neuro-Physics-aware Models for Inverse Problems
- 31.05.2024: Promptable Game Models (Invited Expert Lecture at 3D Vision Summer School 2024)
- 18.04.2024: How to Read Academic Papers (CVMLCG'24 talk)
- 08.12.2022: Advances in Quantum Computer Vision at the Workshop on Quantum Information (event poster).
- 27.04.2022: EUROGRAPHICS 2022 STAR talk Representing and Rendering Dynamic Content.
- 01.09.2021: SIC Lecture Series talk 3D Computer Vision: From a Classical to a Quantum Perspective.
- 29.04.2021: Virtual CG-Lunch talk Q-Match: Iterative Shape Matching via Quantum Annealing.
- 15.04.2021: CVMLCG Seminar talk How to Give a Good Online Scientific Talk.
Publications
2025
2024
2023
2022
2021
2020
2019 and before (selected publications)

|
Bring Your Rear Cameras for Egocentric 3D Human Pose Estimation. H. Akada, J. Wang, V. Golyanik and C. Theobalt. International Conference on Computer Vision (ICCV), 2025 [paper] [project page] |

|
DuetGen: Music Driven Two-Person Dance Generation via Hierarchical Masked Modeling. A. Ghosh, B. Zhou, R. Dabral, J. Wang, V. Golyanik, C. Theobalt, P. Slusallek and C. Guo. SIGGRAPH Conference Proceedings, 2025 (Oral). [paper] [project page] |
|
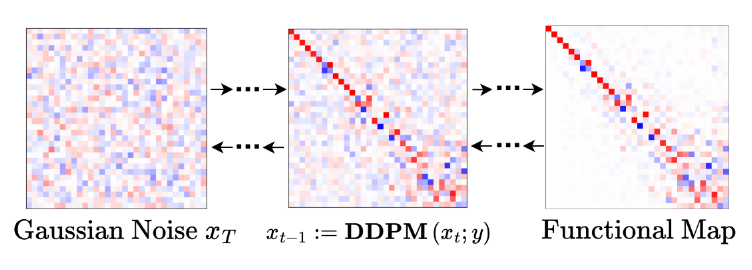
Denoising Functional Maps: Diffusion Models for Shape Correspondence. A. Zhuravlev, Z. Lähner and V. Golyanik. Computer Vision and Pattern Recognition (CVPR), 2025. [paper] [project page] [source code] [dataset] |
|
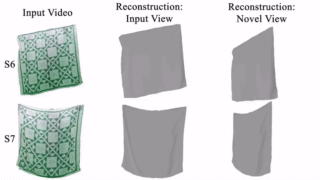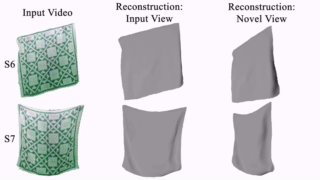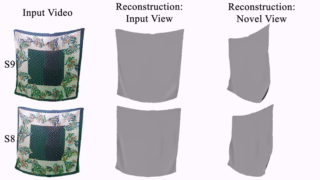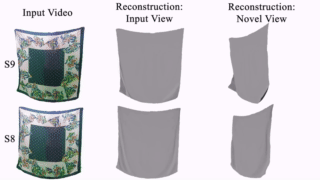
Thin-Shell-SfT: Fine-Grained Monocular Non-rigid 3D Surface Tracking with Neural Deformation Fields. N. Kairanda, M. Habermann, S. Naik, C. Theobalt and V. Golyanik. Computer Vision and Pattern Recognition (CVPR), 2025. [paper] [project page] [video] |
|
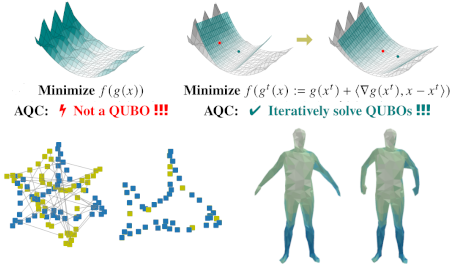
QuCOOP: A Versatile Framework for Solving Composite and Binary-Parametrised Problems on Quantum Annealers. N. Kuete Meli, V. Golyanik, M. Seelbach Benkner and M. Moeller. Computer Vision and Pattern Recognition (CVPR), 2025 (Highlight). [paper] [project page] [video] [source code] |

|
Outlier-Robust Multi-Model Fitting on Quantum Annealers. S. Pandey, L. Magri, F. Arrigoni and V. Golyanik. Computer Vision and Pattern Recognition (CVPR) Workshops, 2025. [paper] [project page] [video] |

|
Dynamic EventNeRF: Reconstructing General Dynamic Scenes from Multi-view RGB and Event Streams. V. Rudnev, G. Fox, M. Elgharib, C. Theobalt, V. Golyanik. Computer Vision and Pattern Recognition (CVPR) Workshops, 2025. [paper] [project page] [source code] [dataset] |

|
BimArt: A Unified Approach for the Synthesis of 3D Bimanual Interaction with Articulated Objects. W. Zhang, R. Dabral, V. Golyanik, V. Coutas, E. Alvarado, T. Beeler, M. Habermann and C. Theobalt. Computer Vision and Pattern Recognition (CVPR), 2025. [paper] [project page] |

|
D-NPC: Dynamic Neural Point Clouds for Non-Rigid View Synthesis from Monocular Video. M. Kappel, F. Hahlbohm, T. Scholz, S. Castillo, C. Theobalt, M. Eisemann, V. Golyanik and M. Magnor. Eurographics 2025 (full paper). [paper] [project page] [source code] [video] |

|
DICE: End-to-end Deformation Capture of Hand-Face Interactions from a Single Image. Q. Wu, Z. Dou, S. Xu, S. Shimada, C. Wang, Z. Yu, Y. Liu, C. Lin, Z. Cao, T. Komura, V. Golyanik, C. Theobalt, W. Wang and L. Liu. ICLR 2025. [paper] [project page] [source code] [video] |

|
EventEgo3D++: 3D Human Motion Capture from a Head-Mounted Event Camera. C. Millerdurai, H. Akada, J. Wang, D. Luvizon, A. Pagani, D. Stricker, C. Theobalt and V. Golyanik. Accepted in International Journal for Computer Vision (IJCV), 2025. [paper] [project page] [source code] [new dataset] |

|
E-3DGS: Event-Based Novel View Rendering of Large-Scale Scenes Using 3D Gaussian Splatting. S. Zahid, V. Rudnev, E. Ilg and V. Golyanik. International Conference on 3D Vision (3DV), 2025. [paper] [project page] [poster] |

|
Betsu-Betsu: Separable 3D Reconstruction of Two Interacting Objects from Multiple Views. S. Gopal, R. Dabral, V. Golyanik and C. Theobalt. International Conference on 3D Vision (3DV), 2025. [paper] [project page] [poster] |
2024
|
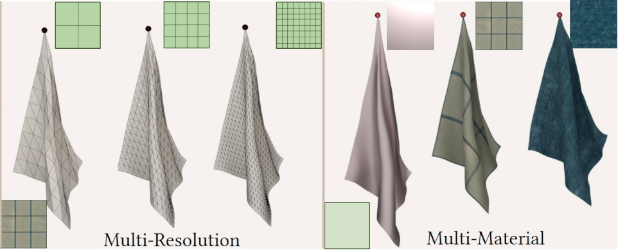
NeuralClothSim: Neural Deformation Fields Meet the Thin Shell Theory. N. Kairanda, M. Habermann, C. Theobalt and V. Golyanik. Neural Information Processing Systems (NeurIPS), 2024. [paper] [project page] [source code] |
|
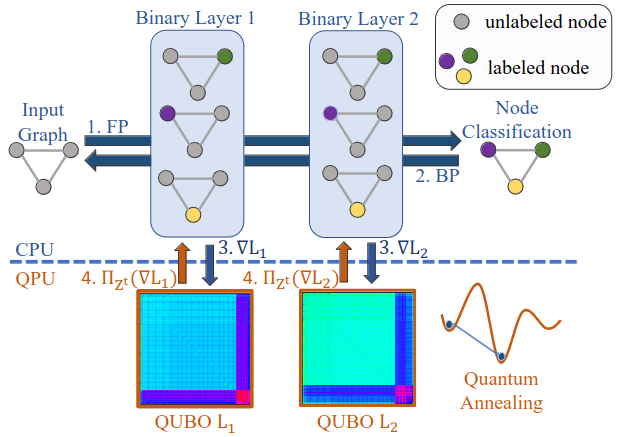
Projected Stochastic Gradient Descent with Quantum Annealed Binary Gradients. M. Krahn, M. Sasdelli, F. Yang, V. Golyanik, J. Kannala, T.-J. Chin and T. Birdal. Accepted at British Machine Vision Conference (BMVC), 2024. [paper] [project page] |

|
ReMoS: 3D Motion-Conditioned Reaction Synthesis for Two-Person Interactions. A. Ghosh, R. Dabral, V. Golyanik, C. Theobalt and P. Slusallek. European Conference on Computer Vision (ECCV), 2024. [paper] [project page] [dataset] |

|
Relightable Neural Actor with Intrinsic Decomposition and Pose Control. D. Luvizon, V. Golyanik, A. Kortylewski, M. Habermann and C. Theobalt. European Conference on Computer Vision (ECCV), 2024. [paper] [project page] [source code] [data] |

|
Promptable Game Models: Text-Guided Game Simulation via Masked Diffusion Models. W. Menapace, A. Siarohin, S. Lathuilière, P. Achlioptas, V. Golyanik, S. Tulyakov and E. Ricci. ACM Transactions on Graphics (ToG), 2024 (presented at SIGGRAPH 2024). [paper] [project page] [github] [bibtex] |
|
|
EventEgo3D: 3D Human Motion Capture from Egocentric Event Streams. C. Millerdurai, H. Akada, J. Wang, D. Luvizon, C. Theobalt and V. Golyanik. Computer Vision and Pattern Recognition (CVPR), 2024. [paper] [project page] |

|
3D Human Pose Perception from Egocentric Stereo Videos.
H. Akada, J. Wang, V. Golyanik and C. Theobalt.
Computer Vision and Pattern Recognition (CVPR), 2024; CVPR Highlight. [paper] [project page] [UnrealEgo Benckmark] |
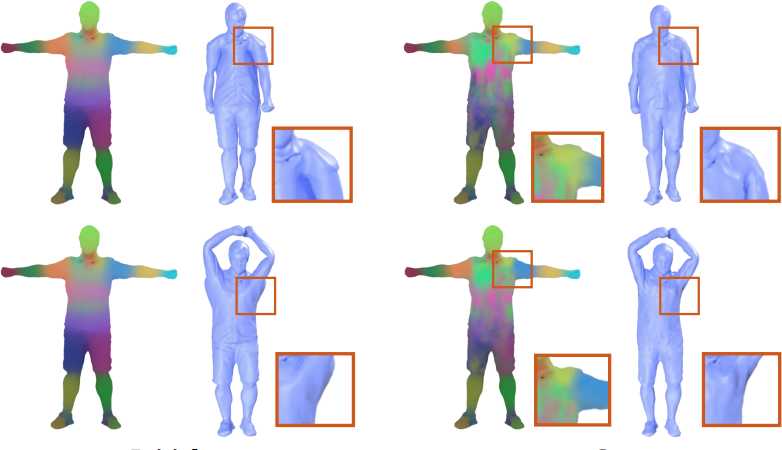
|
VINECS: Video-based Neural Character Skinning. Z. Liao, V. Golyanik, M. Habermann and C. Theobalt. Computer Vision and Pattern Recognition (CVPR), 2024. [paper] |

|
Holoported Characters: Real-time Free-viewpoint Rendering of Humans from Sparse RGB Cameras. A. Shetty, M. Habermann, G. Sun, D. Luvizon, V. Golyanik and C. Theobalt. Computer Vision and Pattern Recognition (CVPR), 2024. [paper] [project page] |

|
State of the Art on Diffusion Models for Visual Computing. R. Po*, W. Yifan*, V. Golyanik*, K. Aberman, J. Barron, A. H. Bermano, E. R. Chan, T. Dekel, A. Holynski, A. Kanazawa, C. K. Liu, L. Liu, B. Mildenhall, M. Niessner, B. Ommer, C. Theobalt, P. Wonka and G. Wetzstein. *Equal contribution Eurographics 2024 (Full STARs). [paper] [project page] [bibtex] |
|
Recent Trends in 3D Reconstruction of General Non-Rigid Scenes. R. Yunus, J. E. Lenssen, M. Niemeyer, Y. Liao, C, Rupprecht, C. Theobalt, G. Pons-Moll, J.-B. Huang, V. Golyanik and E. Ilg. Eurographics 2024 (Full STARs). [paper] [talk slides] [project page] [bibtex] |

|
Fast Non-Rigid Radiance Fields from Monocularized Data. M. Kappel, V. Golyanik, S. Castillo, C. Theobalt and M. Magnor. IEEE Transactions on Visualization and Computer Graphics (TVCG), 2024. [paper] [project page] [source code] [bibtex] [video] |

|
3D Pose Estimation of Two Interacting Hands from a Monocular Event Camera. C. Millerdurai, D. Luvizon, V. Rudnev, A. Jonas, J. Wang, C. Theobalt and V. Golyanik. International Conference on 3D Vision (3DV), 2024; Spotlight [paper] [project page] [poster] |

|
Quantum-Hybrid Stereo Matching With Nonlinear Regularization and Spatial Pyramids. C. Braunstein, E. Ilg and V. Golyanik. International Conference on 3D Vision (3DV), 2024. [paper] [project page] |
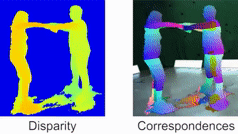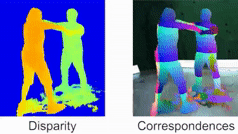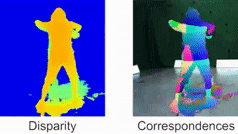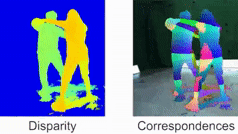
|
SceNeRFlow: Time-Consistent Reconstruction of General Dynamic Scenes. E. Tretschk, V. Golyanik, M. Zollhöfer, A. Bozic, C. Lassner and C. Theobalt. International Conference on 3D Vision (3DV), 2024. [paper] [project page] |

|
ROAM: Robust and Object-aware Motion Generation using Neural Pose Descriptors. W. Zhang, R. Dabral, T. Leimkühler, V. Golyanik*, M. Habermann* and C. Theobalt. * equal advising and contribution. International Conference on 3D Vision (3DV), 2024. [paper] [project page] |

|
MACS: Mass-Conditioned 3D Hand and Object Motion Synthesis. S. Shimada, F. Mueller, J. Bednařík, B. Doosti, B. Bickel, D. Tang, V. Golyanik, J. Taylor, C. Theobalt and T. Beeler. International Conference on 3D Vision (3DV), 2024. [paper] [project page] |
2023

|
Decaf: Monocular Deformation Capture for Face and Hand Interactions. S. Shimada, V. Golyanik, P. Pérez, and C. Theobalt. ACM Transactions on Graphics (TOG), SIGGRAPH Asia, 2023. [paper] [project page] [supplementary video] |
|
|
AvatarStudio: Text-driven Editing of 3D Dynamic Human Head Avatars. M. Mendiratta, X. Pan, M. Elgharib, K. Teotia, Mallikarjun B R, A. Tewari, V. Golyanik, A. Kortylewski and C. Theobalt. ACM Transactions on Graphics (TOG), SIGGRAPH ASIA, 2023. [arxiv] [project page] |

|
Discovering Fatigued Movements for Virtual Character Animation. N. Cheema, R, Xu, N. H. Kim, P. Hämäläinen, V. Golyanik, M. Habermann, C. Theobalt, P. Slusallek. SIGGRAPH ASIA, 2023 (conference paper). [arxiv] [project page] |
|
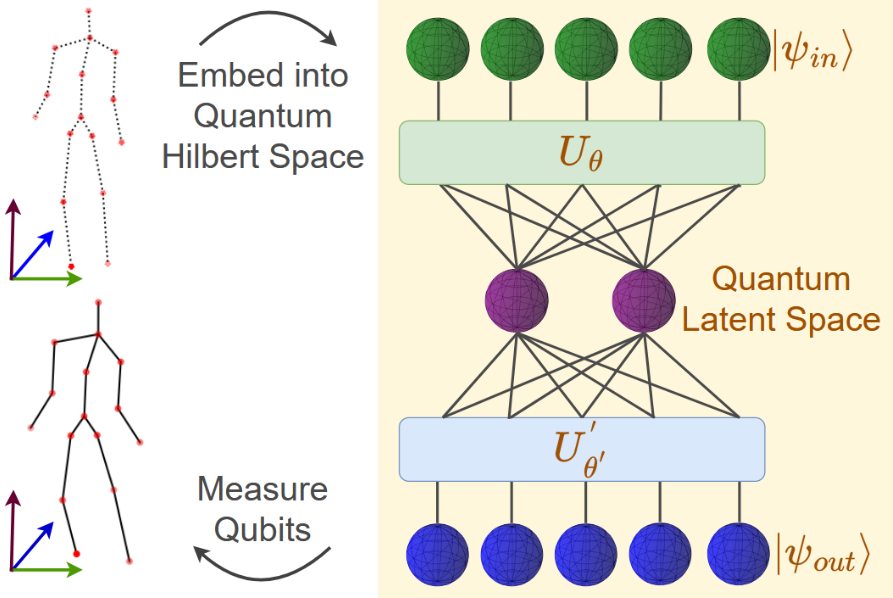
3D-QAE: Fully Quantum Auto-Encoding of 3D Point Clouds. L. Rathi, E. Tretschk, C. Theobalt, R. Dabral and V. Golyanik. British Machine Vision Conference (BMVC), 2023. [paper] [project page] |

|
EgoLocate: Real-time Motion Capture, Localization, and Mapping with Sparse Body-mounted Sensors. X. Yi, Y. Zhou, M. Habermann, V. Golyanik, S. Pan, C. Theobalt and F. Xu. SIGGRAPH, 2023. [arxiv] [project page] [source code] |
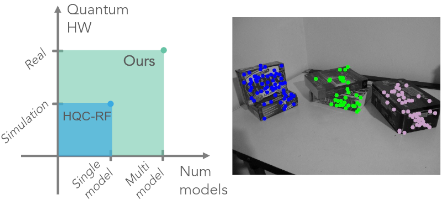
|
Quantum Multi-Model Fitting.
M. Farina, L. Magri, W. Menapace, E. Ricci, V. Golyanik and F. Arrigoni.
Computer Vision and Pattern Recognition (CVPR), 2023; CVPR Highlight (selected 10%). [paper] [project page] [source code] |

|
MoFusion: A Framework for Denoising-Diffusion-based Motion Synthesis.
R. Dabral, M. H. Mughal, V. Golyanik and C. Theobalt.
Computer Vision and Pattern Recognition (CVPR), 2023; CVPR Highlight (selected 10%). [paper] [project page] [bibtex] |

|
EventNeRF: Neural Radiance Fields from a Single Colour Event Camera. V. Rudnev, M. Elgharib, C. Theobalt, V. Golyanik. Computer Vision and Pattern Recognition (CVPR), 2023. [paper] [project page] [bibtex] |

|
CCuantuMM: Cycle-Consistent Quantum-Hybrid Matching of Multiple Shapes. H. Bhatia, E. Tretschk, Z. Lähner, M. Seelbach Benkner, M. Moeller, C. Theobalt and V. Golyanik. Computer Vision and Pattern Recognition (CVPR), 2023. [paper] [project page] [source code] |
|
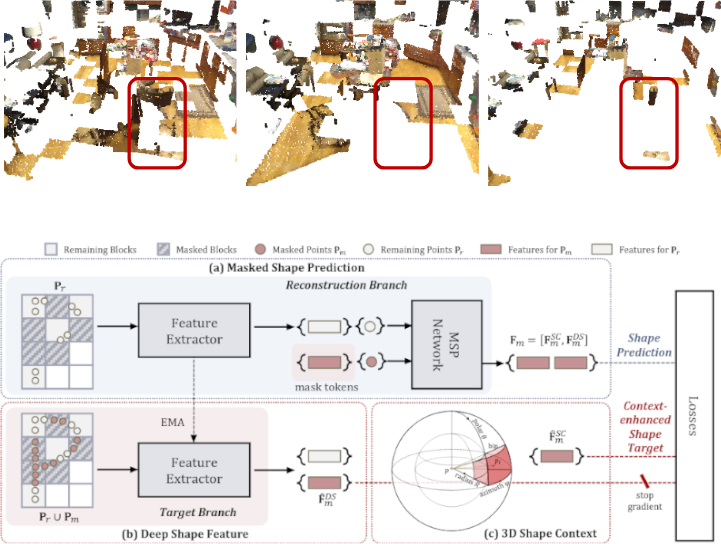
Self-supervised Pre-training with Masked Shape Prediction for 3D Scene Understanding. L. Jiang, Z. Yang, S. Shi, V. Golyanik, D. Dai and B. Schiele. Computer Vision and Pattern Recognition (CVPR), 2023. [paper] |
|
|
Unbiased 4D: Monocular 4D Reconstruction with a Neural Deformation Model. E. C. M. Johnson, M. Habermann, S. Shimada, V. Golyanik and C. Theobalt. Computer Vision and Pattern Recognition (CVPR) Workshops, 2023. [paper] [project page] [source code] [data] [bibtex] |
|
|
QuAnt: Quantum Annealing with Learnt Couplings.
M. Seelbach Benkner, M. Krahn, E. Tretschk, Z. Lähner, M. Moeller and V. Golyanik. International Conference on Learning Representations (ICLR), 2023; Oral (top 25% of the accepted papers). [project page] [paper] [bibtex] |
|
|
State of the Art in Dense Monocular Non-Rigid 3D Reconstruction. E. Tretschk*, N. Kairanda*, M. B R, R. Dabral, A. Kortylewski, B. Egger, M. Habermann, P. Fua, C. Theobalt and V. Golyanik. * equal contribution. Eurographics 2023 (Full STARs). [draft] [project page] [bibtex] |

|
Scene-Aware 3D Multi-Human Motion Capture from a Single Camera. D. Luvizon, M. Habermann, V. Golyanik, A. Kortylewski and C. Theobalt. Eurographics 2023. [paper] [project page] |
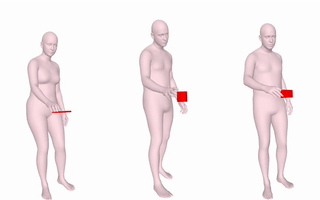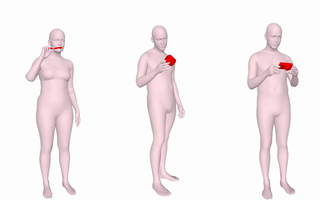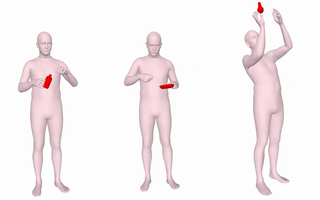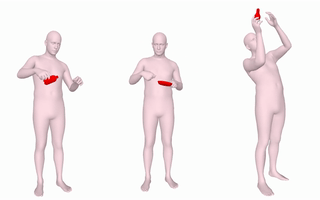
|
IMoS: Intent-Driven Full-Body Motion Synthesis for Human-Object Interactions. A. Ghosh, R. Dabral, V. Golyanik, C. Theobalt and P. Slusallek. Eurographics 2023. [project page] [paper] [bibtex] |
2022

|
HiFECap: Monocular High-Fidelity and Expressive Capture of Human Performances. Y. Jiang, M. Habermann, V. Golyanik and C. Theobalt. British Machine Vision Conference (BMVC), 2022. [project page] [paper] [bibtex] |
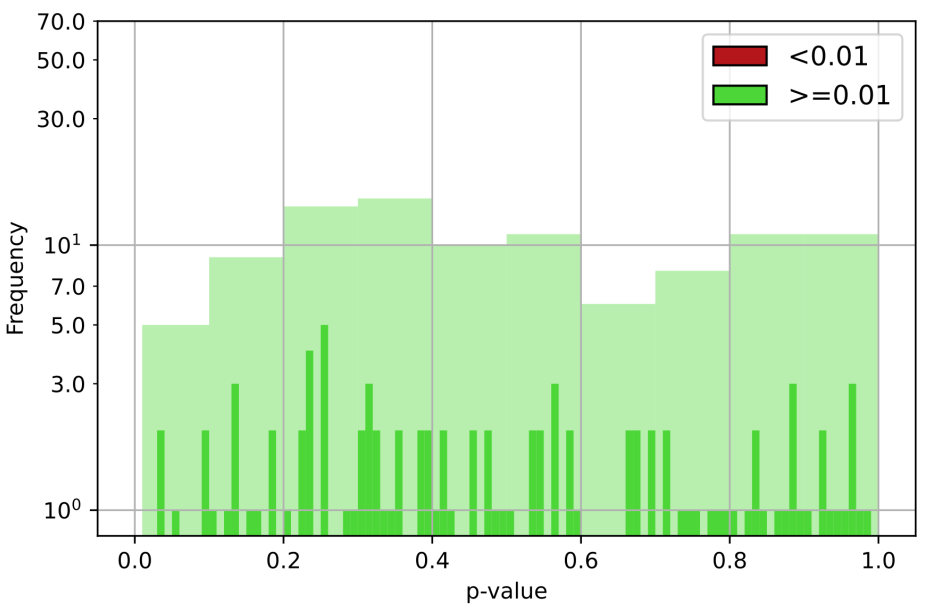
|
Generation of Truly Random Numbers on a Quantum Annealer. H. Bhatia, E. Tretschk, C. Theobalt and V. Golyanik. IEEE Access 2022. [project page] [paper] [bibtex] |
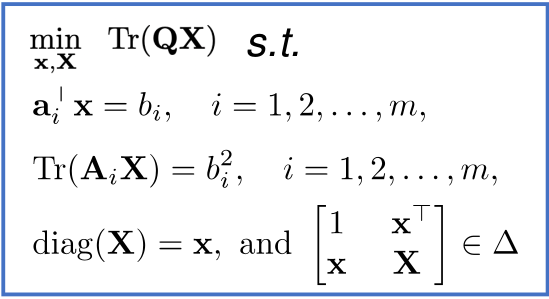
|
Q-FW: A Hybrid Classical-Quantum Frank-Wolfe for Quadratic Binary Optimization. A. Yurtsever, T. Birdal and V. Golyanik. European Conference on Computer Vision (ECCV), 2022. [project page] [paper] [bibtex] [poster] |

|
UnrealEgo: A New Dataset for Robust Egocentric 3D Human Motion Capture. H. Akada, J. Wang, S. Shimada, M. Takahashi, C. Theobalt and V. Golyanik. European Conference on Computer Vision (ECCV), 2022. [project page] [paper] [bibtex] |
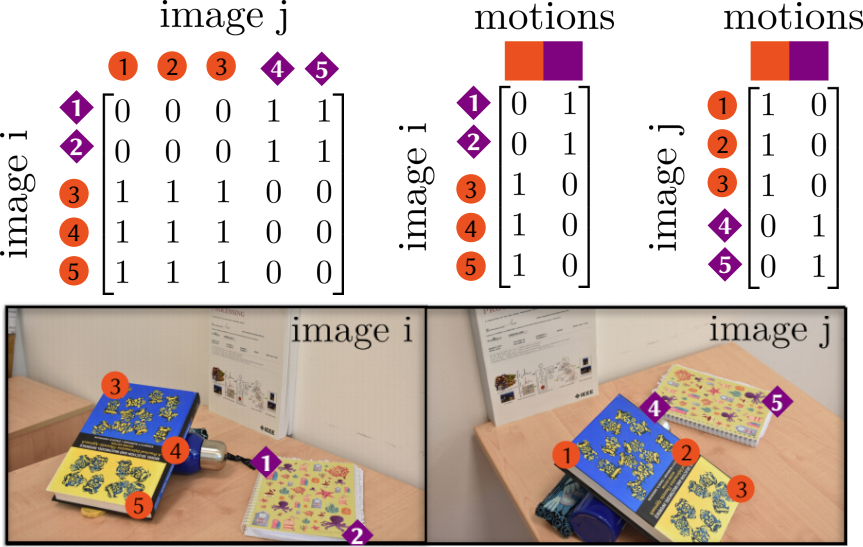
|
Quantum Motion Segmentation. F. Arrigoni, W. Menapace, M. Seelbach Benkner, E. Ricci and V. Golyanik. European Conference on Computer Vision (ECCV), 2022. [project page] [paper] [bibtex] |

|
HULC: 3D HUman Motion Capture with Pose Manifold Sampling and Dense Contact Guidance. S. Shimada, V. Golyanik, Z. Li, P. Pérez, W. Xu and C. Theobalt. European Conference on Computer Vision (ECCV), 2022. [paper] [project page] |

|
Neural Radiance Fields for Outdoor Scene Relighting. V. Rudnev, M. Elgharib, W. Smith, L. Liu, V. Golyanik and C. Theobalt. European Conference on Computer Vision (ECCV), 2022. [paper] [project page] [bibtex] |

|
MoCapDeform: Monocular 3D Human Motion Capture in Deformable Scenes. Z. Li, S. Shimada, B. Schiele, C. Theobalt and V. Golyanik. International Conference on 3D Vision (3DV), 2022; Oral. Best Student Paper Award. [project page] [paper] [bibtex] |
|
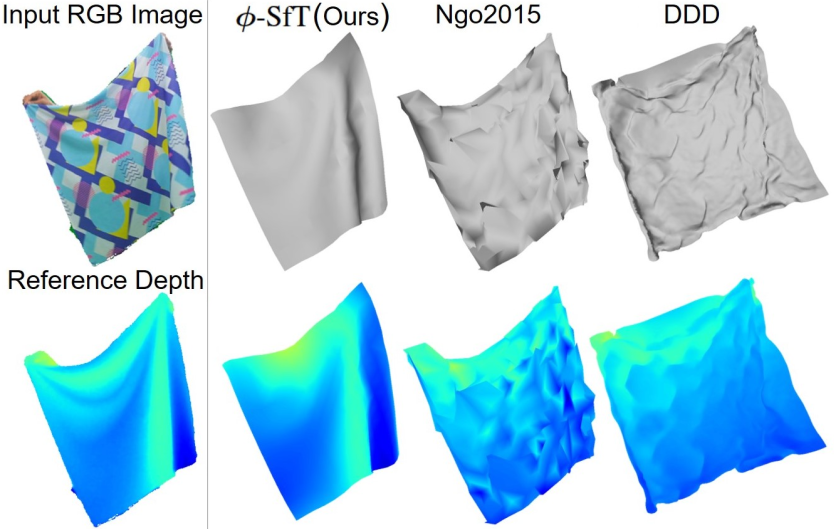
φ-SfT: Shape-from-Template with a Physics-Based Deformation Model. N. Kairanda, E. Tretschk, M. Elgharib, C. Theobalt and V. Golyanik. Computer Vision and Pattern Recognition (CVPR), 2022. [paper] [project page] [source code] [bibtex] |

|
Physical Inertial Poser (PIP): Physics-aware Real-time Human Motion Tracking from Sparse Inertial Sensors. X. Yi, Y. Zhou, M. Habermann, S. Shimada, V. Golyanik, C. Theobalt and F. Xu. Computer Vision and Pattern Recognition (CVPR), 2022. Best Paper Finalist (one out of 33, 1.6% of the accepted papers) [paper] [project page] [source code] [bibtex] |

|
Playable Environments: Video Manipulation in Space and Time. W. Menapace, S. Lathuilière*, A. Siarohin, C. Theobalt*, S. Tulyakov*, V. Golyanik*, and E. Ricci*. * equal senior contribution. Computer Vision and Pattern Recognition (CVPR), 2022. [paper] [project page] [github] [bibtex] |
|
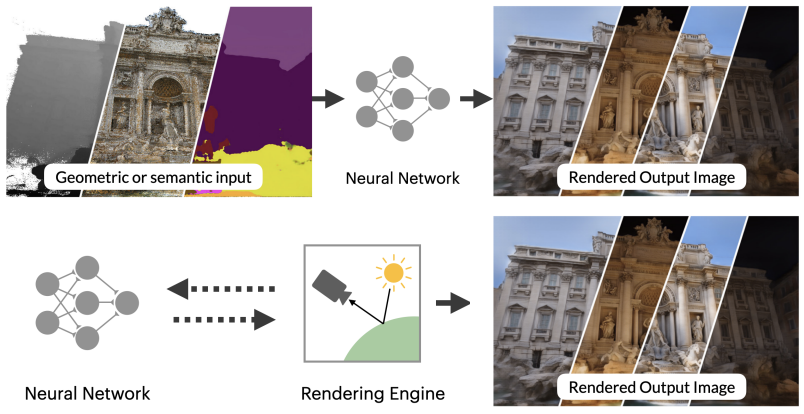
Advances in Neural Rendering. A. Tewari*, J. Thies*, B. Mildenhall*, P. Srinivasan*, E. Tretschk, Y. Wang, C. Lassner, V. Sitzmann, R. Martin-Brualla, S. Lombardi, C. Theobalt, M. Niessner, J. T. Barron, G. Wetzstein, M. Zollhöfer and V. Golyanik. * equal contribution. State of the Art Report at Eurographics 2022. [paper] [project page] [bibtex] |
2021
|
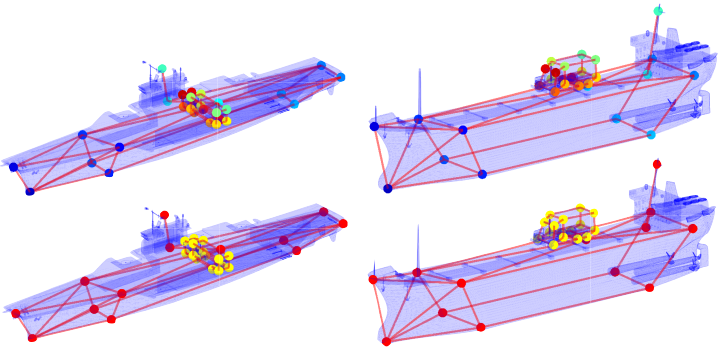
Convex Joint Graph Matching and Clustering via Semidefinite Relaxations. M. Krahn, F. Bernard and V. Golyanik. International Conference on 3D Vision (3DV), 2021. [paper] [project page] [bibtex] |

|
HumanGAN: A Generative Model of Human Images. K. Sarkar, L. Liu, V. Golyanik, and C. Theobalt. International Conference on 3D Vision (3DV), 2021; Oral [paper] [project page] [bibtex] |
|
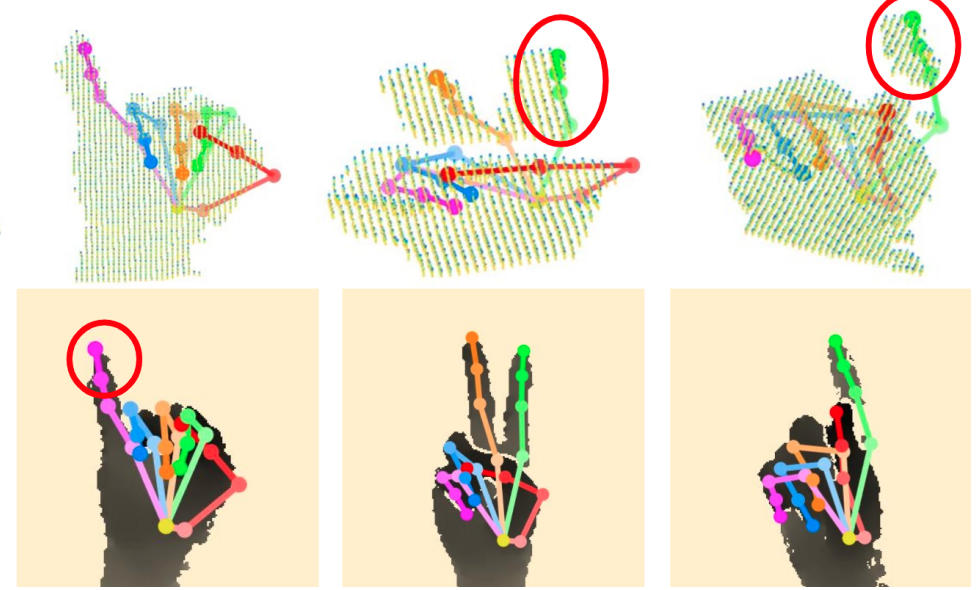
HandVoxNet++: 3D Hand Shape and Pose Estimation using Voxel-Based Neural Networks. J. Malik, S. Shimada, A. Elhayek, S. A. Ali, C. Theobalt, V. Golyanik and D. Stricker. Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2021. [IEEE Xplore] [arXiv.org] [project page] [bibtex] |

|
Gravity-Aware 3D Human-Object Reconstruction. R. Dabral, S. Shimada, A. Jain, C. Theobalt and V. Golyanik. International Conference on Computer Vision (ICCV), 2021. [paper] [project page] [bibtex] |
|
|
Q-Match: Iterative Shape Matching via Quantum Annealing. M. Seelbach Benkner, Z. Lähner, V. Golyanik, C. Wunderlich, C. Theobalt and M. Moeller. International Conference on Computer Vision (ICCV), 2021. [paper] [project page] [bibtex] |
|
|
EventHands: Real-Time Neural 3D Hand Pose Estimation from an Event Stream. V. Rudnev, V. Golyanik, J. Wang, H.-P. Seidel, F. Mueller, M. Elgharib and C. Theobalt. International Conference on Computer Vision (ICCV), 2021. Featured in "ICCV 2021 Daily" (link) [paper] [project page] [source code] [bibtex] |
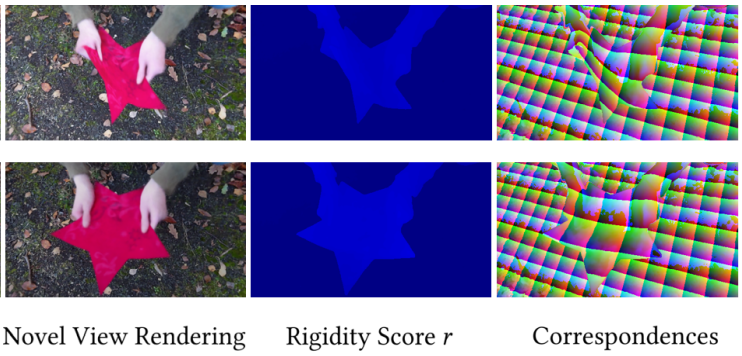
|
Non-Rigid Neural Radiance Fields: Reconstruction and Novel View Synthesis of a Deforming Scene from Monocular Video. E. Tretschk, A. Tewari, V. Golyanik, M. Zollhöfer, C. Lassner and C. Theobalt. International Conference on Computer Vision (ICCV), 2021. [paper] [project page] [source code] [bibtex] |

|
Neural Monocular 3D Human Motion Capture with Physical Awareness.("Neural PhysCap") S. Shimada, V. Golyanik, W. Xu, P. Pérez and C. Theobalt. SIGGRAPH, 2021. [paper] [arXiv] [bibtex] [project page] [source code] |
|
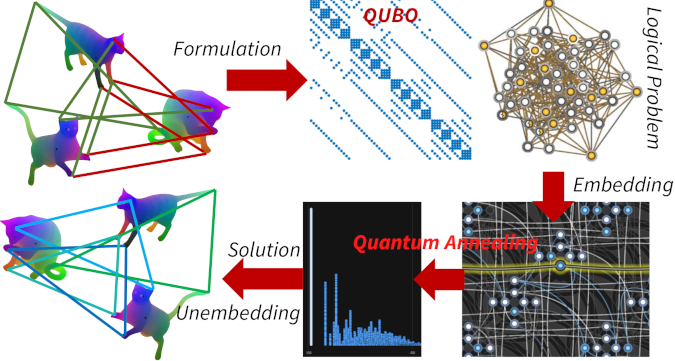
Quantum Permutation Synchronization. T. Birdal*, V. Golyanik*, C. Theobalt and L. Guibas. * equal contribution. Computer Vision and Pattern Recognition (CVPR), 2021. [paper] [arXiv] [project page] [project page (github)] [bibtex] |
|
|
High-Fidelity Neural Human Motion Transfer from Monocular Video. M. Kappel, V. Golyanik, M. Elgharib, J.-O. Henningson, H.-P. Seidel, S. Castillo, C. Theobalt and M. Magnor. Computer Vision and Pattern Recognition (CVPR), 2021; Oral. [paper] [project page] [bibtex] [source code] |

|
Pose-Guided Human Animation from a Single Image in the Wild. J. S. Yoon, L. Liu, V. Golyanik, K. Sarkar, H. S. Park, and C. Theobalt. Computer Vision and Pattern Recognition (CVPR), 2021. [paper] [project page] [video] [bibtex] |
|
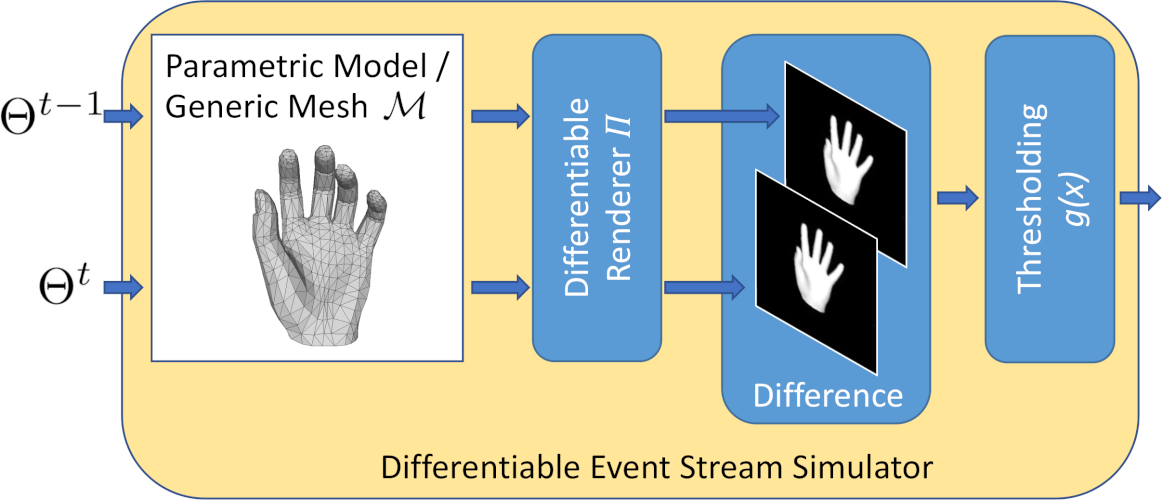
Differentiable Event Stream Simulator for Non-Rigid 3D Tracking. J. Nehvi, V. Golyanik, F. Mueller, H.-P. Seidel, M. Elgharib and C. Theobalt. CVPR Workshop on Event-based Vision, 2021. [paper] [arXiv] [supplement] [source code (upon request)] [bibtex] [project page] |
|
|
Fast Gravitational Approach for Rigid Point Set Registration with Ordinary Differential Equations. S. A. Ali, K. Kahraman, C. Theobalt, D. Stricker and V. Golyanik. IEEE Access, 2021. [paper] [arXiv] [project page] [bibtex] |
2020
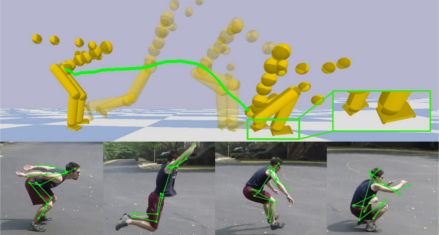
|
PhysCap: Physically Plausible Monocular 3D Motion Capture in Real Time. S. Shimada, V. Golyanik, W. Xu and C. Theobalt. SIGGRAPH Asia, 2020. [paper (arXiv.org)] [bibtex] [project page] |
|
|
Egocentric Videoconferencing. M. Mendiratta*, M. Elgharib*, J. Thies, M. Nießner, H.-P. Seidel, A. Tewari, V. Golyanik and C. Theobalt. * equal contribution. SIGGRAPH Asia, 2020. [draft] [supplement] [bibtex] [project page] |
|
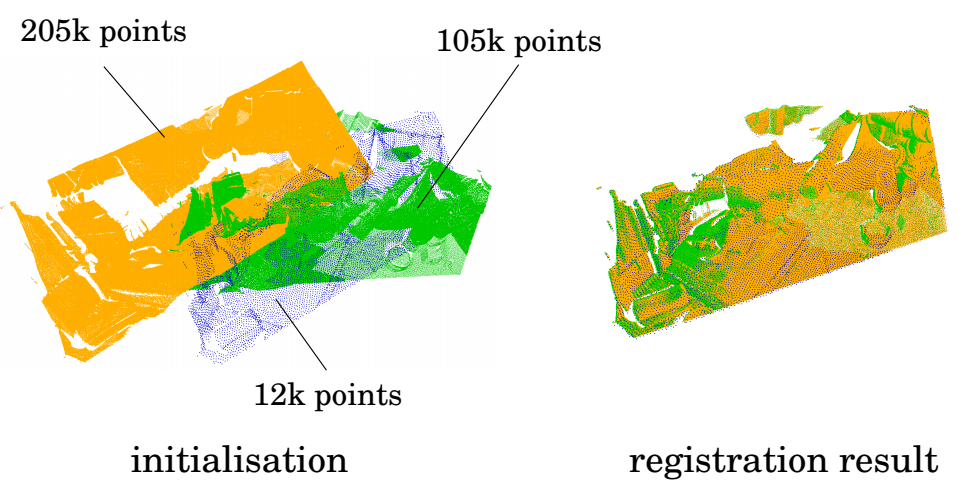
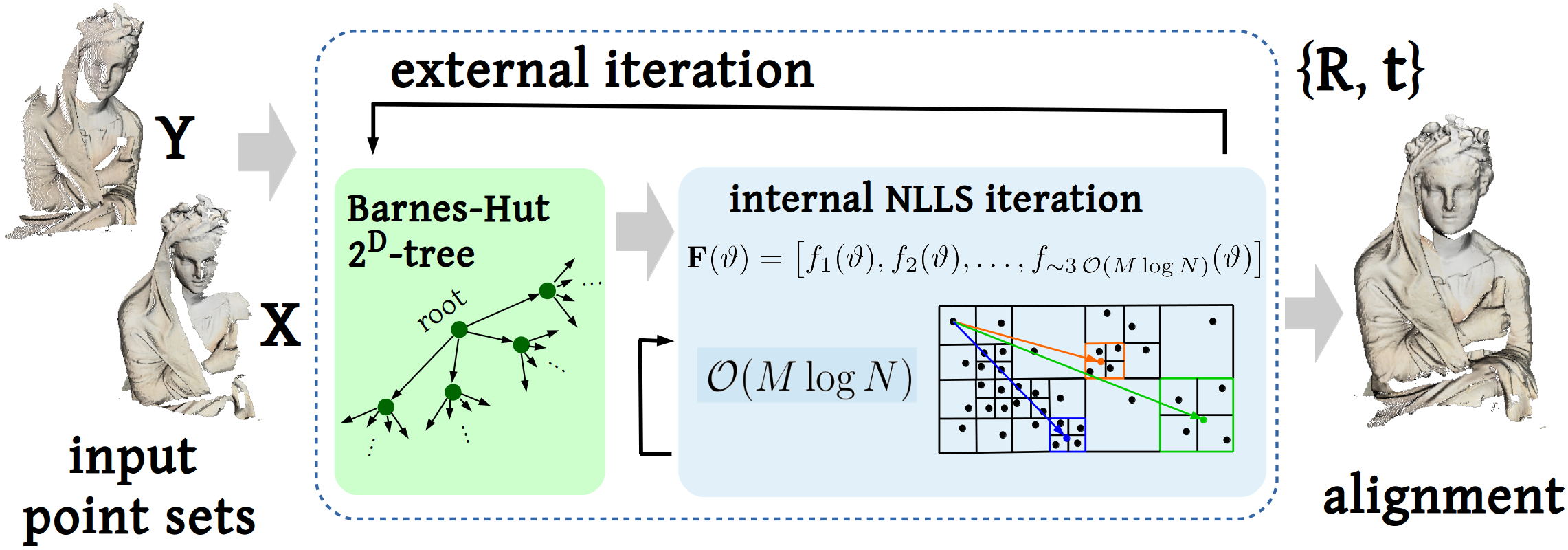
Fast Simultaneous Gravitational Alignment of Multiple Point Sets. V. Golyanik, S. Shimada and C. Theobalt. 3DV, 2020; Oral. [draft] [bibtex] [project page] |
|
|
Adiabatic Quantum Graph Matching with Permutation Matrix Constraints. M. Seelbach Benkner, V. Golyanik, C. Theobalt and M. Moeller. 3DV, 2020. [draft] [supplement] [bibtex] [project page] |
|
Intrinsic Dynamic Shape Prior for Dense Non-Rigid Structure from Motion. V. Golyanik, A. Jonas, D. Stricker and C. Theobalt. 3DV, 2020. [draft] [bibtex] [extended version (arXiv)] [3DV talk] [project page] |
|
|
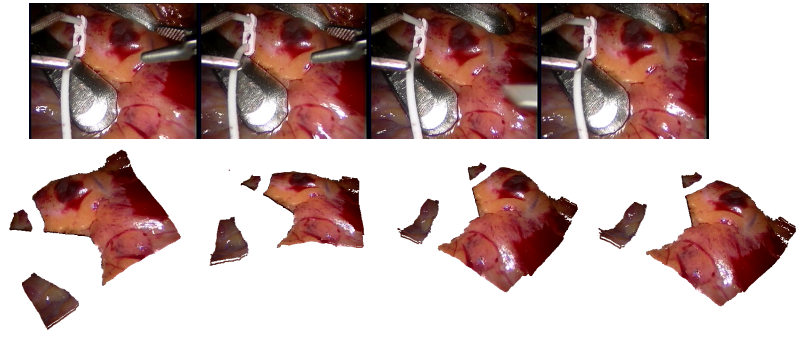
Neural Dense Non-Rigid Structure from Motion with Latent Space Constraints. V. Sidhu, E. Tretschk, V. Golyanik, A. Agudo and C. Theobalt. European Conference on Computer Vision (ECCV), 2020. [paper] [supplement] [video] [bibtex] [project page (includes the ECCV talks)] |
|
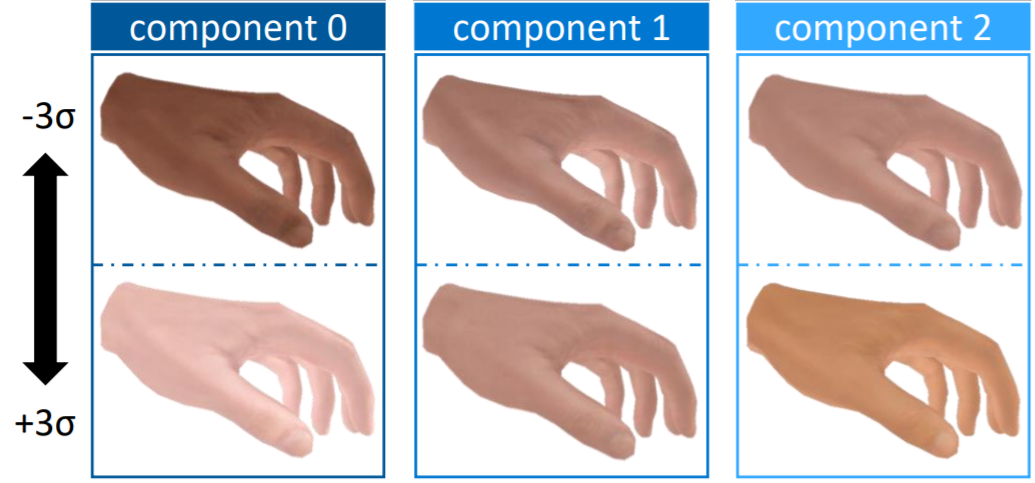
HTML: A Parametric Hand Texture Model for 3D Hand Reconstruction and Personalization. N. Qian, J. Wang, F. Müller, F. Bernard, V. Golyanik and C. Theobalt. European Conference on Computer Vision (ECCV), 2020. [paper] [supplement] [video] [bibtex] [project page] |
|
|
PatchNets: Patch-Based Generalizable Deep Implicit 3D Shape Representations. E. Tretschk, A. Tewari, V. Golyanik, M. Zollhöfer, C. Stoll and C. Theobalt. European Conference on Computer Vision (ECCV), 2020. [paper] [supplement] [video] [bibtex] [project page (includes the ECCV talks)] [source code] |

|
DEMEA: Deep Mesh Autoencoders for Non-Rigidly Deforming Objects. E. Tretschk, A. Tewari, M. Zollhöfer, V. Golyanik and C. Theobalt. European Conference on Computer Vision (ECCV), 2020; Spotlight [paper] [supplement] [bibtex] [arXiv] [project page (includes the ECCV talks)] |
|
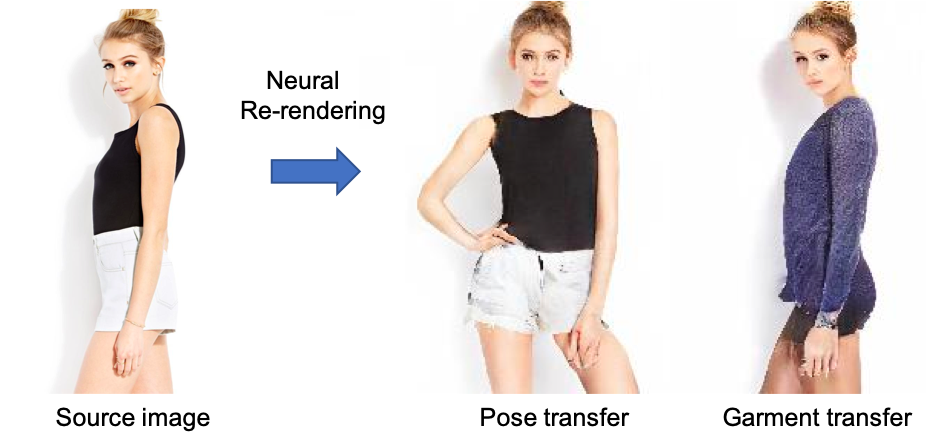
Neural Re-Rendering of Humans from a Single Image. K. Sarkar, D. Mehta, W. Xu, V. Golyanik and C. Theobalt. European Conference on Computer Vision (ECCV), 2020. Featured in "ECCV 2020 Daily" (link) [paper] [supplement] [video] [bibtex] [project page] |

|
A Quantum Computational Approach to Correspondence Problems on Point Sets. V. Golyanik and C. Theobalt. In Computer Vision and Pattern Recognition (CVPR), 2020. [paper] [slides] [poster] [bibtex] [arXiv] [project page] |
|
|
EventCap: Monocular 3D Capture of High-Speed Human Motions using an Event Camera. L. Xu, W. Xu, V. Golyanik, M. Habermann, L. Fang and C. Theobalt. In Computer Vision and Pattern Recognition (CVPR), 2020; Oral [paper] [supplement] [bibtex] [arXiv] [project page] |
|
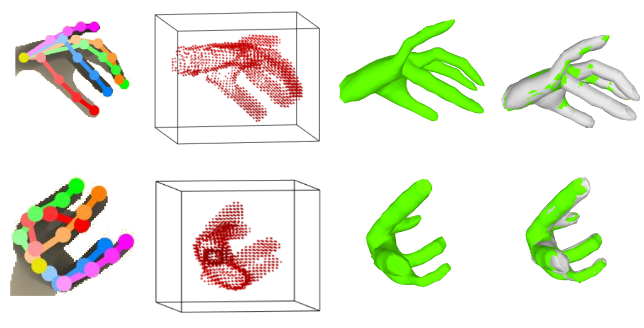
HandVoxNet: Deep Voxel-Based Network for 3D Hand Shape and Pose Estimation from a Single Depth Map. J. Malik, I. Abdelaziz, A. Elhayek, S. Shimada, S. A. Ali, V. Golyanik, C. Theobalt and D. Stricker. In Computer Vision and Pattern Recognition (CVPR), 2020. [paper] [supplement] [bibtex] [arXiv] [project page] |

|
Robust Methods for Dense Monocular Non-Rigid 3D Reconstruction and Alignment of Point Clouds. Doctoral Dissertation, TU Kaiserslautern. V. Golyanik. Springer Vieweg Verlag, 2020. DAGM MVTec Dissertation Award 2020 [Springer] [Springer Link] [Book Flyer] |
2019 and before (selected publications)
|
Structure from Articulated Motion: Accurate and Stable Monocular 3D Reconstruction without Training Data. O. Kovalenko, V. Golyanik, J. Malik, A. Elhayek and D. Stricker. Sensors (Volume 19, Issue 20), 2019. [paper] [project page] |
|
Accelerated Gravitational Point Set Alignment with Altered Physical Laws. V. Golyanik, C. Theobalt and D. Stricker. International Conference on Computer Vision (ICCV), 2019; [paper] [supplementary material] [poster] [bibtex] [project page] |
|
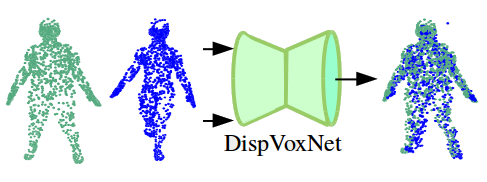
DispVoxNets: Non-Rigid Point Set Alignment with Supervised Learning Proxies. S. Shimada, V. Golyanik, E. Tretschk, D. Stricker and C. Theobalt. In International Conference on 3D Vision (3DV), 2019; Oral [paper] [poster] [presentation] [project page] [arXiv] [bibtex] |
|
|
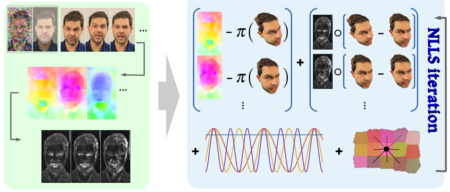
IsMo-GAN: Adversarial Learning for Monocular Non-Rigid 3D Reconstruction. S. Shimada, V. Golyanik, C. Theobalt and D. Stricker. Computer Vision and Pattern Recognition Workshops (Photogrammetric Computer Vision Workshop), 2019; Oral [paper] [bibtex] [arXiv] [project page] |
|
Consolidating Segmentwise Non-Rigid Structure from Motion. V. Golyanik, A. Jonas and D. Stricker. Machine Vision Applications (MVA), 2019; Oral [paper] [project page] [bibtex] |
|
|
NRGA: Gravitational Approach for Non-Rigid Point Set Registration. S. A. Ali. V. Golyanik and D. Stricker. International Conference on 3D Vision (3DV), 2018; Oral [paper] [Supplementary Video (Download, YouTube)] [poster] [bibtex] |
|
|
HDM-Net: Monocular Non-Rigid 3D Reconstruction with Learned Deformation Model. V. Golyanik, S. Shimada, K. Varanasi and D. Stricker. EuroVR, 2018; Oral (Long Paper) [paper] [HDM-Net data set] [bibtex] |
|
|
Multiframe Scene Flow with Piecewise Rigid Motion. V. Golyanik, K. Kim, R. Maier, M. Nießner, D. Stricker and J. Kautz. International Conference on 3D Vision (3DV), 2017; Spotlight Oral [paper] [arXiv] [supplementary material] [poster] [bibtex] |
|
|
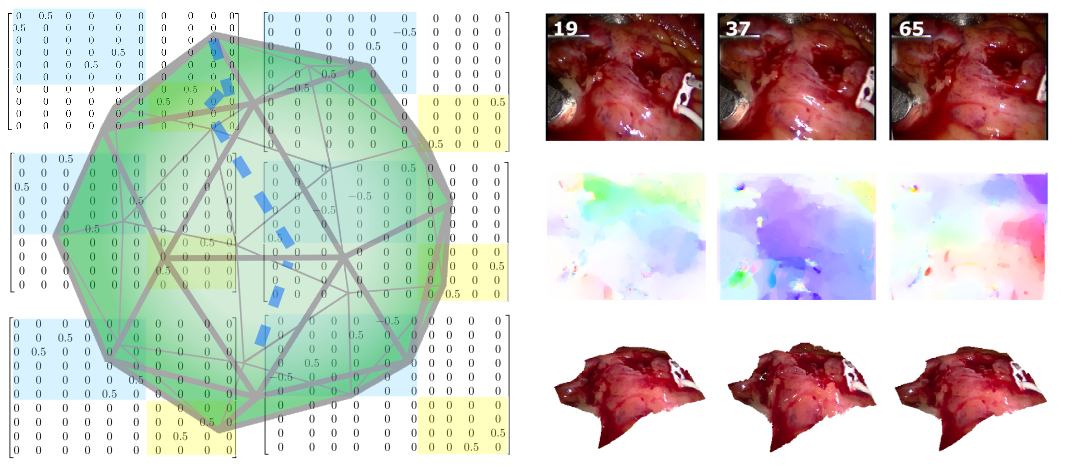
Scalable Dense Monocular Surface Reconstruction. M.D.Ansari, V. Golyanik and D. Stricker. International Conference on 3D Vision (3DV), 2017. [paper] [arXiv] [bibtex] |
|
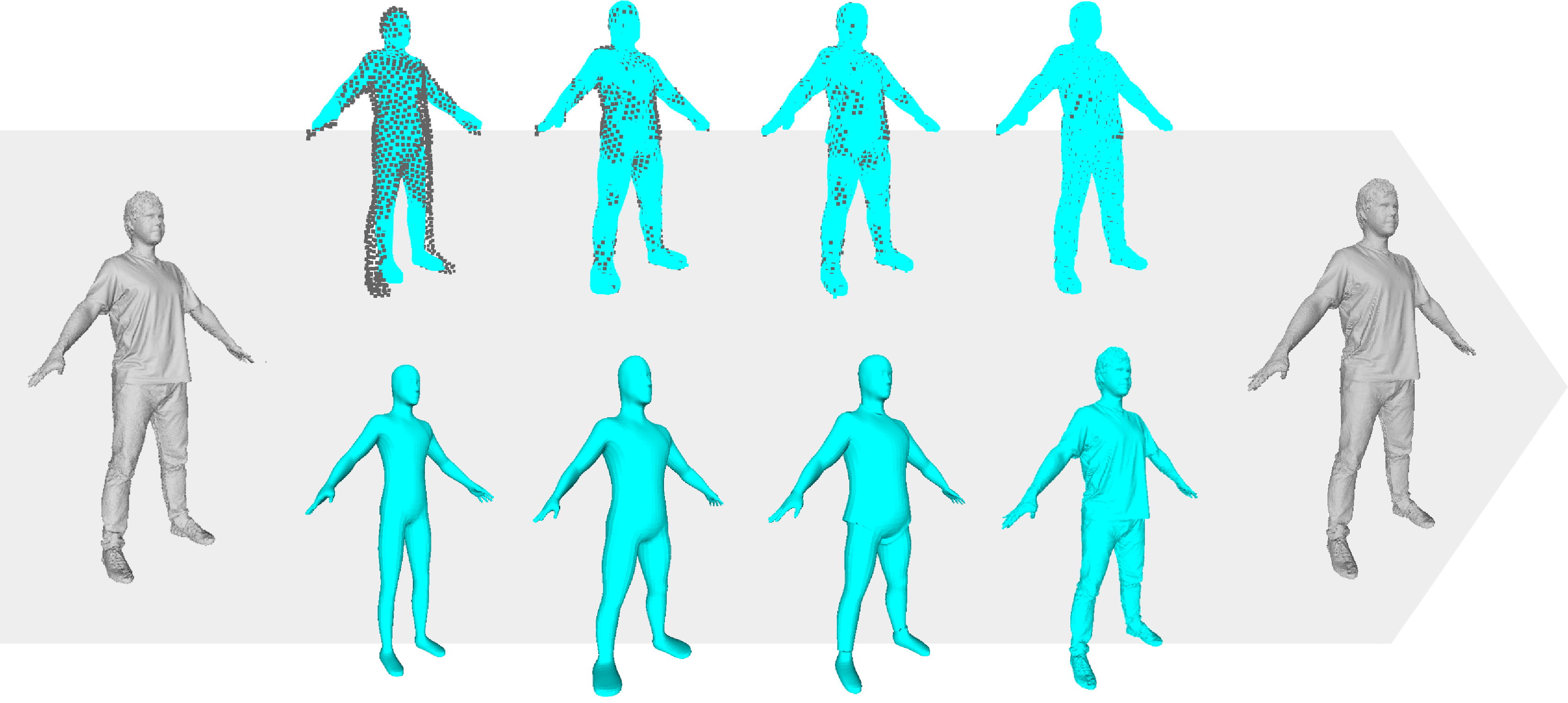
A Framework for an Accurate Point Cloud Based Registration of Full 3D Human Body Scans. V. Golyanik, G. Reis, B. Taetz and D. Stricker. Machine Vision Applications (MVA), 2017. [paper] [bibtex] |
|
Dense Batch Non-Rigid Structure from Motion in a Second. V. Golyanik and D. Stricker. Winter Conference on Applications of Computer Vision (WACV), 2017. [paper] [supplementary video] [poster] [bibtex] |

|
Accurate 3D Reconstruction of Dynamic Scenes from Monocular Image Sequences with Severe Occlusions. V. Golyanik, T. Fetzer and D. Stricker. Winter Conference on Applications of Computer Vision (WACV), 2017. [paper] [supplementary material] [poster] [arXiv] [bibtex] |
|
|
Gravitational Approach for Point Set Registration. V. Golyanik, S. A. Ali and D. Stricker. Computer Vision and Pattern Recognition (CVPR), 2016. [paper] [supplementary material] [bibtex] |
|
|
Extended Coherent Point Drift Algorithm with Correspondence Priors and Optimal Subsampling. V. Golyanik, B. Taetz, G. Reis and D. Stricker. Winter Conference on Applications of Computer Vision (WACV), 2016. [paper] [poster] [bibtex] [WACV Talk] |
|
|
Occlusion-Aware Video Registration for Highly Non-Rigid Objects. B. Taetz, G. Bleser, V. Golyanik and D. Stricker. Winter Conference on Applications of Computer Vision (WACV), 2016. Best Paper Award. [paper] [supplementary material] [bibtex] [WACV Talk] |